Java slower on Solaris than Windows?
CLICK HERE FOR LATEST ARTICLE
As part of my job, I have been writing some Java code to do some pretty complex data moving and processing, and was getting great performance results on my laptop. The next step was to test the performance on a "Production" system - usually thought of as Unix/Linux. The first test was on Solaris. To my disappointment, the numbers weren't that great.
So I created a little benchmark class (others must have also done this before, but nothing was handy) to rule out any of the processing and test the performance of basic functions. This class does 5 things:
1) A simple for loop with a billion iterations
2) A loop doing simple FP processing (d = 34.0, for(..) d= (d* 23.7)/56.9
3) Writing a 50MB filling it with ASCII '0123456789' repeated
4) Reading that file using fis.read()
5) Reading the file using a 1MB memory map block read
The results I got kind of shocked me, so I was wondering if anyone could shed any light on them. Both of these results are using exactly the same code, JSDK1.4.2, and the same VM params (Client [HotSpot] mode).
Windows XP on my Laptop: Dell Latitude 600, 1.6GHz, 1GB Ram
If anyone could repeat this test (its just a simple Java file - you can download it here) and past the results as comments here, I'd really appreciate it. I would like to know if this is expected behavior for Solaris, or if our machine needs its kernel tuned. I have also tried it on our AIX, Linux and HP-UX machines, using Xeon and Itanium processors and gotten equally disappointing results.
Technorati Tags: java, benchmark, solaris, windows, programming, performance
As part of my job, I have been writing some Java code to do some pretty complex data moving and processing, and was getting great performance results on my laptop. The next step was to test the performance on a "Production" system - usually thought of as Unix/Linux. The first test was on Solaris. To my disappointment, the numbers weren't that great.
So I created a little benchmark class (others must have also done this before, but nothing was handy) to rule out any of the processing and test the performance of basic functions. This class does 5 things:
1) A simple for loop with a billion iterations
2) A loop doing simple FP processing (d = 34.0, for(..) d= (d* 23.7)/56.9
3) Writing a 50MB filling it with ASCII '0123456789' repeated
4) Reading that file using fis.read()
5) Reading the file using a 1MB memory map block read
The results I got kind of shocked me, so I was wondering if anyone could shed any light on them. Both of these results are using exactly the same code, JSDK1.4.2, and the same VM params (Client [HotSpot] mode).
Windows XP on my Laptop: Dell Latitude 600, 1.6GHz, 1GB Ram
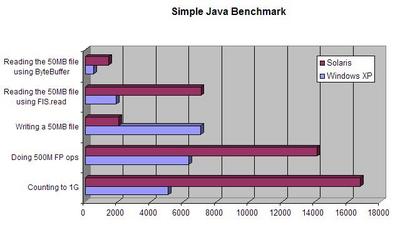
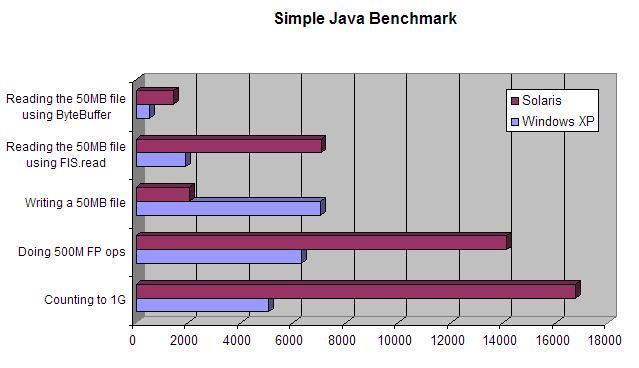
Starting BenchmarkSun-Fire-V440 Solaris 5.10, 2x1GHz, 4GB Ram
Counting to 1,000,000,000...took 5060ms
Doing 500,000,000 FP ops...took 6320ms
Writing a 50MB file...took 7043ms
Reading the 50MB file using FIS.read...took 1893ms
Reading the 50MB file using ByteBuffer...took 531ms
Starting BenchmarkSo the basic iterations were 3 1/2 times slower, writing a file 3 1/2 times faster, but reading 3 1/2 times slower on Solaris than Windows.
Counting to 1,000,000,000...took 16753ms
Doing 500,000,000 FP ops...took 14140ms
Writing a 50MB file...took 2031ms
Reading the 50MB file using FIS.read...took 7058ms
Reading the 50MB file using ByteBuffer...took 1430ms
If anyone could repeat this test (its just a simple Java file - you can download it here) and past the results as comments here, I'd really appreciate it. I would like to know if this is expected behavior for Solaris, or if our machine needs its kernel tuned. I have also tried it on our AIX, Linux and HP-UX machines, using Xeon and Itanium processors and gotten equally disappointing results.
Technorati Tags: java, benchmark, solaris, windows, programming, performance
posted by BXCellent at 1:43 PM
![]()
![]()


3 Comments:
You may want to try a set of different JVMs. I run your BenchMark class on my Windows 2000 with java 1.4 from Sun and IBM and got the following results:
java version "1.4.1"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.4.1)
Classic VM (build 1.4.1, J2RE 1.4.1 IBM Windows 32 build cn1411-20031011 (JIT enabled: jitc))
Starting Benchmark
Counting to 1,000,000,000...took 1328ms
Doing 500,000,000 FP ops...took 0ms
Writing a 50MB file...took 4094ms
Reading the 50MB file using FIS.read...took 1984ms
Reading the 50MB file using ByteBuffer...took 469ms
java version "1.4.2_03"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.4.2_03-b02)
Java HotSpot(TM) Client VM (build 1.4.2_03-b02, mixed mode)
Starting Benchmark
Counting to 1,000,000,000...took 4000ms
Doing 500,000,000 FP ops...took 11751ms
Writing a 50MB file...took 5656ms
Reading the 50MB file using FIS.read...took 2125ms
Reading the 50MB file using ByteBuffer...took 562ms
On Solaris we are still on Java 1.3, so it would not run due to lack of nio support.
Einar
There is also a subtle technical issue at work here. The difference is in the chips... as they say. In college I worked on a pure java parallel simulation engine. http://www.cs.oswego.edu/~wender/eclpss/ (currently cleaning stuff up on my own time) We have an 8 way V880 server to test things out on. It always seemed a tad slower then they should be. My dual Athlon was able to keep pace pretty well, for instance. I theorized this was due to the difference in Sparc vs x86 architecture. Sparc chips have 32 general purpose registers, while x86 chips have less then a hand full. To compile code for a Sparc you must do a lot of "register painting", attempting to optimized register usage for the code being executed. Unfortunately, because of the JIT, Java loses twice. First it loses out in taking extra runtime to _do_ register painting, then it loses again because it can't do that good of a job at it, and register allocation is far from optimal. Work on bettering this is proceeding with hotspot, but it's tough work! Email me if you would like to talk further.
On an old Enterprise 450
java version "1.5.0-rc"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0-rc-b63)
Java HotSpot(TM) Server VM (build 1.5.0-rc-b63, mixed mode)
Starting Benchmark
Counting to 1,000,000,000...took 22ms
Doing 500,000,000 FP ops...took 89ms
Writing a 50MB file...took 3457ms
Reading the 50MB file using FIS.read...took 16721ms
Reading the 50MB file using ByteBuffer...took 3957ms
I just wanted to post this and mention that your Benchmark (like most) isn't meaningful in a lot of cases. Java 1.5 is apparently optimizing away empty loops and doing other magic here. ;)
Post a Comment
<< Home